

Data analysis in Python revolves around a fundamental abstraction that transformed how we work with structured data: the DataFrame. While many developers use DataFrames daily, truly understanding this powerful abstraction is essential. This deep understanding unlocks more effective data manipulation patterns and builds transferable knowledge that extends across the entire data science ecosystem.
Why Understanding DataFrames Matters
The DataFrame represents a paradigm shift in how we think about and manipulate data. Traditional approaches were heavily influenced by rigid database schemas and row-oriented thinking. DataFrames introduced a more fluid, column-centric approach that better matches how analysts actually work with data.
This mental model has become the foundation for modern data science workflows across languages and platforms. Whether you’re working with Pandas, PySpark, R’s data.frame, or distributed systems, the core DataFrame concepts provide a unified framework for data manipulation.
From Single Cabinet to Filing System
In our Series fundamentals guide, we explored how a Pandas Series works like a sophisticated filing cabinet - each drawer labeled with meaningful indices, containing your data values. Now, imagine expanding this concept: what if you had multiple filing cabinets arranged side by side, all sharing the same drawer labels?
That’s exactly what a DataFrame is: a collection of aligned filing cabinets (Series) that share the same drawer labels (index).
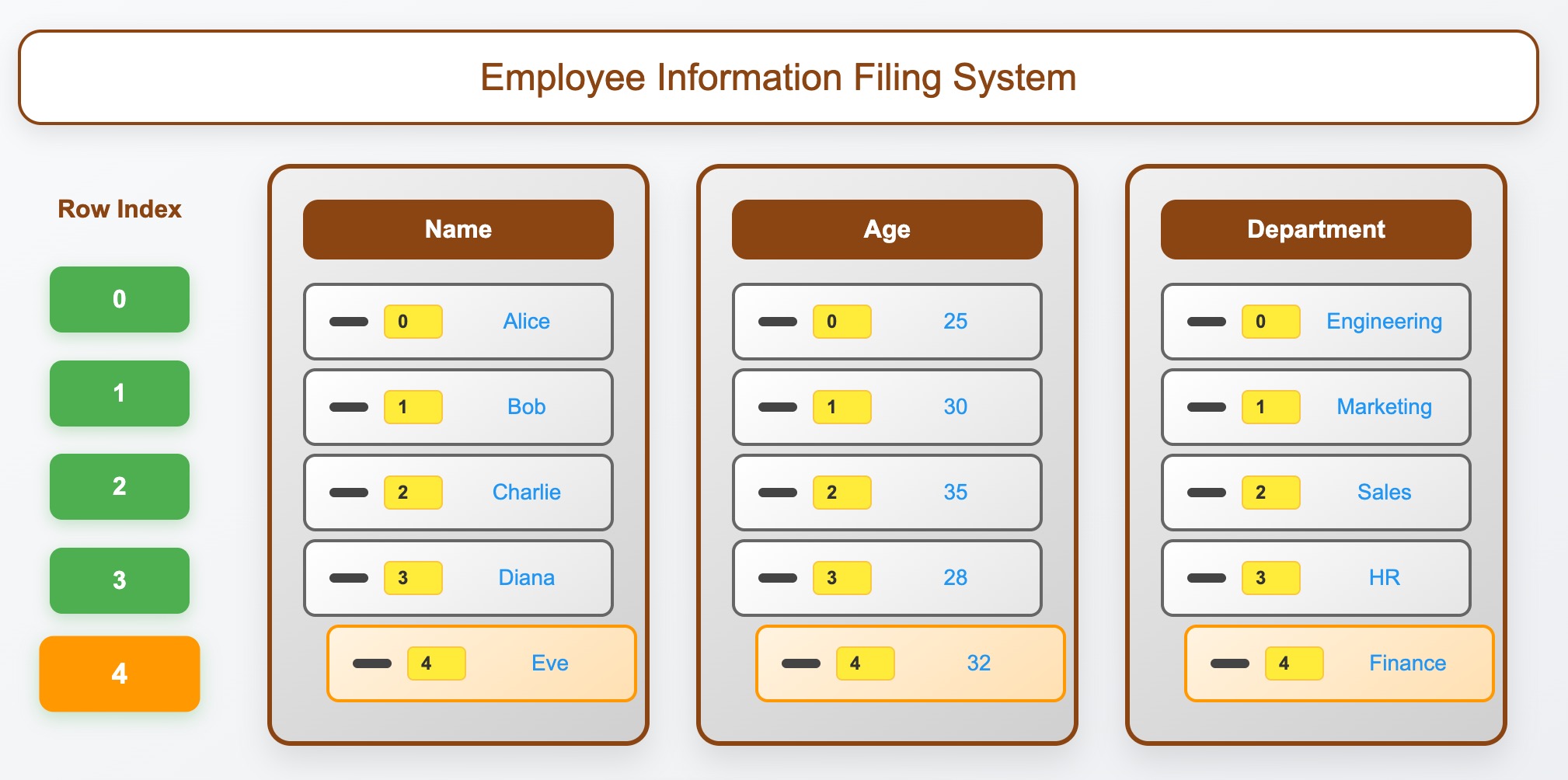
The Extended Filing Cabinet System
Think of a DataFrame as an organized filing system where:
- Each filing cabinet is a Series (column) containing one type of information
- Each drawer level represents a row (shared index across all cabinets)
- All cabinets have identical drawer labels (aligned indices)
- Each cabinet stores different types of items (different data types per column)
- You can find any item by cabinet + drawer label (column + row coordinates)
Let’s see this filing system in action:
import pandas as pd
import numpy as np
# Individual filing cabinets (Series) - each with identical drawer labels
names_cabinet = pd.Series(['Alice', 'Bob', 'Charlie', 'Diana', 'Eve'], index=[0, 1, 2, 3, 4])
ages_cabinet = pd.Series([25, 30, 35, 28, 32], index=[0, 1, 2, 3, 4])
departments_cabinet = pd.Series(['Engineering', 'Marketing', 'Sales', 'HR', 'Finance'],
index=[0, 1, 2, 3, 4])
print("Individual filing cabinets (Series):")
print(f"Names Cabinet:\n{names_cabinet}\n")
print(f"Ages Cabinet:\n{ages_cabinet}\n")
print(f"Departments Cabinet:\n{departments_cabinet}\n")
# Now arrange them side by side in our filing system (DataFrame)
employee_filing_system = pd.DataFrame({
'name': names_cabinet,
'age': ages_cabinet,
'department': departments_cabinet
})
print("Complete Filing System (DataFrame):")
print(employee_filing_system)
Notice how each drawer level (row) contains related information about the same person across all cabinets, while each cabinet (column) contains the same type of information for all people. This alignment is automatic and powerful.
Why This Filing System Design Is Revolutionary
Unlike traditional database tables that think in terms of complete records (rows), our DataFrame filing system thinks in terms of aligned filing cabinets (columns). This shift changes everything:
# Traditional database thinking: complete records
# INSERT INTO employees VALUES ('Alice', 25, 50000, 'Engineering')
# DataFrame thinking: aligned cabinets with shared drawer labels
print("Access entire cabinets (columns):")
print(f"All names from the name cabinet: {employee_filing_system['name'].tolist()}")
print(f"All ages from the age cabinet: {employee_filing_system['age'].tolist()}")
print(f"All departments: {employee_filing_system['department'].tolist()}")
# Cross-cabinet operations (filtering)
print(f"\nEngineering employees: {employee_filing_system[employee_filing_system['department'] == 'Engineering']['name'].tolist()}")
The Filing System’s Flexible Design
Our filing system has remarkable flexibility:
- Add new cabinets anytime: No predefined schema required
- Each cabinet has its own storage type: Different data types per column
- Shared drawer labels: All cabinets use the same index labels
- Easy expansion: Transform, add, or remove cabinets as needed
# Each cabinet can store different types of items
print("\nCabinet storage types:")
print(employee_filing_system.dtypes)
# Output:
# name object (text)
# age int64 (numbers)
# department object (text)
print("\nFiling system with all cabinets:")
print(employee_filing_system)
The Filing System’s Design Principles
Composability: Multiple Filing Systems, One Office
Just as you can arrange multiple filing systems in the same office, DataFrames can be combined and transformed. Each filing system (DataFrame) is made of cabinets (Series), and systems can be merged, joined, or arranged side by side:
# Start with our main filing system
print("Main Employee Filing System:")
print(employee_filing_system)
# Create a separate filing system with additional employee data
training_system = pd.DataFrame({
'training_hours': [40, 25, 60, 35, 45],
'certifications': [2, 1, 4, 2, 3]
}, index=[0, 1, 2, 3, 4])
print("\nTraining Filing System:")
print(training_system)
# Combine the filing systems (merge DataFrames)
combined_office = pd.concat([employee_filing_system, training_system], axis=1)
print("\nComplete Office (combined filing systems):")
print(combined_office)
print(f"\nCabinet types across office: \n{combined_office.dtypes}")
Notice how filing systems can be combined seamlessly when they share the same drawer labels (index), creating a larger office of information.
Labeling System: Finding Items by Cabinet + Drawer
In our filing system, every item has a clear address: Drawer Label + Cabinet Name. This labeling system is much better than just saying “3rd drawer from the top in the 2nd cabinet” (positions):
# Clear labeling: Drawer (row) + Cabinet (column)
print("Using cabinet labels (recommended):")
print(f"# Access specific drawer in specific cabinet (cell)")
print(f"Alice's age: {employee_filing_system.loc[0, 'age']}")
print(f"Bob's department: {employee_filing_system.loc[1, 'department']}")
# Access entire drawer across all cabinets (row)
print(f"\nCharlie's complete information:")
print(employee_filing_system.loc[2])
# Access specific cabinet (column)
print(f"\nAll names:")
print(employee_filing_system['name'])
# Reorganize filing system by department drawers
print("\nReorganizing filing system by department drawers:")
dept_system = employee_filing_system.set_index('department')
print(f"Everything in Engineering drawers:\n{dept_system.loc['Engineering']}")
System-Wide Operations: Transform Entire Cabinets at Once
The real power of our filing system comes from being able to operate on entire filing cabinets simultaneously, rather than going drawer by drawer:
# System-wide operations: transform entire cabinets at once
print("System-wide transformations:")
# Create new cabinets based on existing ones
employee_filing_system['salary'] = [50000, 75000, 80000, 65000, 72000] # Add salary cabinet
employee_filing_system['performance'] = [8.5, 7.2, 9.1, 8.8, 8.0] # Add performance cabinet
employee_filing_system['years_experience'] = [3, 8, 12, 5, 6] # Add experience cabinet
# Give everyone a 10% salary increase (entire salary cabinet)
employee_filing_system['new_salary'] = employee_filing_system['salary'] * 1.10
# Add calculated cabinet based on existing cabinets
employee_filing_system['bonus'] = employee_filing_system['salary'] * (employee_filing_system['performance'] / 10)
print("Filing system with calculated cabinets:")
print(employee_filing_system[['name', 'salary', 'new_salary', 'performance', 'bonus', 'years_experience']])
# This cabinet-wide approach is much faster than:
# for drawer in employee_filing_system.index:
# employee_filing_system.loc[drawer, 'new_salary'] = employee_filing_system.loc[drawer, 'salary'] * 1.10
Operating on entire cabinets (vectorized operations) is not just faster—it’s a fundamentally different way of thinking about data transformations.
Advanced Filing Concepts: Multi-Level Drawer Systems
Hierarchical Drawers: Sub-Drawers Within Drawers
Sometimes you need more complex labeling than just “Drawer + Cabinet.” Imagine a filing system where each main drawer has sub-drawers - like “North Region, Q1” and “North Region, Q2”:
# Multi-level filing system: Regional sales with quarterly data
sales_filing_system = pd.DataFrame({
'revenue': [100000, 120000, 95000, 110000, 85000, 90000, 88000, 95000],
'units_sold': [1000, 1200, 950, 1100, 850, 900, 880, 950]
})
# Create hierarchical drawer system (Region + Quarter)
regions = ['North', 'North', 'North', 'North', 'South', 'South', 'South', 'South']
quarters = ['Q1', 'Q2', 'Q3', 'Q4', 'Q1', 'Q2', 'Q3', 'Q4']
sales_filing_system.index = pd.MultiIndex.from_arrays([regions, quarters],
names=['Region', 'Quarter'])
print("Multi-level filing system:")
print(sales_filing_system)
# Access entire regions or specific sub-drawers
print("\nAll North Region data:")
print(sales_filing_system.loc['North'])
print("\nAll Q1 sub-drawers across regions:")
print(sales_filing_system.loc[(slice(None), 'Q1'), :])
Smart Filing System Connections: Automatic Drawer Matching
When combining filing systems with different drawer labels, our DataFrame systems are smart enough to match up corresponding drawers automatically:
# Two filing systems with different drawer labels
q1_system = pd.DataFrame({'revenue': [100000, 85000]},
index=['North', 'South'])
q2_system = pd.DataFrame({'revenue': [120000, 90000, 75000]},
index=['North', 'South', 'West'])
print("Q1 Filing System (2 drawers):")
print(q1_system)
print("\nQ2 Filing System (3 drawers):")
print(q2_system)
# Smart alignment: matching drawers are combined, missing drawers get NaN
print("\nCombined systems (automatic drawer alignment):")
print(q1_system + q2_system)
# Notice: North + North = combined, South + South = combined, West gets NaN (no Q1 data)
Filing System Analytics: Grouping Drawers for Analysis
# Analyze our filing system by grouping drawers (employees) by department
print("Department-wise filing system analysis:")
dept_analysis = employee_filing_system.groupby('department').agg({
'salary': ['mean', 'min', 'max'],
'performance': 'mean',
'age': 'mean'
})
print(dept_analysis)
# This creates specialized analysis cabinets with multi-level organization
print(f"\nAnalysis cabinet structure: {dept_analysis.columns.tolist()}")
Understanding Filing System Performance: Why Design Matters
Understanding DataFrames means understanding their performance characteristics and design trade-offs:
Cabinet-Oriented Storage Model
Filing systems use a cabinet-oriented storage layout, which has profound implications:
# Demonstrate memory efficiency
print("Memory usage by cabinet:")
print(employee_filing_system.memory_usage(deep=True))
# Cabinet operations are highly optimized
print("\nCabinet-wise operations are fast:")
large_filing_system = pd.DataFrame({
'values': np.random.randn(100000),
'categories': np.random.choice(['A', 'B', 'C'], 100000)
})
# This is very fast because it operates on contiguous storage
result = large_filing_system['values'] * 2
print(f"Processed {len(large_filing_system)} drawers efficiently")
# Storage optimization strategies
print("\nOptimizing storage usage:")
print(f"Original storage: {large_filing_system.memory_usage(deep=True).sum()} bytes")
# Convert to more efficient storage types
large_filing_system['categories'] = large_filing_system['categories'].astype('category')
print(f"After optimization: {large_filing_system.memory_usage(deep=True).sum()} bytes")
The Power of Cabinet-Wide Operations
# Why cabinet-wide operations matter
import time
# Slow: drawer-by-drawer processing
start = time.time()
result_slow = []
for value in large_filing_system['values'][:1000]:
result_slow.append(value * 2)
slow_time = time.time() - start
# Fast: cabinet-wide processing
start = time.time()
result_fast = large_filing_system['values'][:1000] * 2
fast_time = time.time() - start
print(f"Drawer-by-drawer: {slow_time:.4f} seconds")
print(f"Cabinet-wide: {fast_time:.4f} seconds")
print(f"Speedup: {slow_time/fast_time:.1f}x faster")
Understanding Scale Limitations
Filing systems have inherent limitations that inform when to use them:
# Filing systems are in-memory structures
print(f"Current filing system memory: {employee_filing_system.memory_usage(deep=True).sum()} bytes")
print(f"Available system memory determines maximum filing system size")
# For larger datasets, consider:
# 1. Chunked processing (multiple smaller filing systems)
# 2. Dask for out-of-core operations
# 3. Distributed frameworks like PySpark
# 4. Database-backed solutions
The Broader Impact: Why Filing Systems Matter
The DataFrame filing system concept has fundamentally changed how we approach data analysis:
Universal Filing Principles
The filing system mental model has spread far beyond Pandas:
# The same concepts appear across tools:
# - Pandas DataFrame (Python filing systems)
# - R data.frame (R filing systems)
# - Spark DataFrame (distributed filing systems)
# - Polars DataFrame (Rust-based, faster filing)
# - Dask DataFrame (parallel filing systems)
# Core filing concepts remain consistent:
print("Universal filing system concepts:")
print("1. Cabinet-oriented thinking (columns first)")
print("2. Label-based drawer organization (meaningful indices)")
print("3. Cabinet-wide operations (vectorized processing)")
print("4. Flexible filing schemas (dynamic structure)")
print("5. Composable filing systems (easy combination)")
Modern Filing Developments
The filing system abstraction continues to evolve:
- Apache Arrow: Standardized cabinet storage format
- GPU Acceleration: RAPIDS cuDF for massive filing systems
- Lazy Evaluation: Polars and other modern implementations
- Type Safety: Enhanced filing type systems for safer operations
- Distributed Filing: Seamless scaling across multiple offices
Key Takeaways: The Filing System Mental Model
DataFrames represent more than just a data structure—they embody a fundamental approach to data organization. Understanding DataFrames deeply means grasping:
Core Filing Principles
- Composition over Complexity: Build complex systems from simple cabinets (Series)
- Labels over Positions: Use meaningful drawer labels instead of numeric positions
- Cabinets as First-Class Citizens: Think cabinet-wise, not drawer-wise
- Cabinet-Wide over Drawer-by-Drawer: Operate on entire cabinets at once
- Automatic Alignment: Let the system handle drawer matching between cabinets
Transferable Filing Patterns
# These patterns work across all DataFrame filing systems:
print("Universal filing system patterns:")
print("- filing_system.groupby('cabinet').agg(function)")
print("- filing_system.loc[drawer_condition, cabinet_list]")
print("- filing_system['new_cabinet'] = filing_system['cabinet1'] + filing_system['cabinet2']")
print("- filing_system.merge(other_system, on='key')")
print("- filing_system.pivot_table(values='val', index='idx', columns='col')")
Why This Filing Understanding Matters
Mastering DataFrame filing concepts provides:
- Tool Independence: Core filing patterns transfer across platforms
- Performance Intuition: Understanding when filing operations will be fast or slow
- Design Thinking: How to organize data for effective analysis
- Debugging Skills: Recognizing common filing patterns and anti-patterns
Looking Forward
The DataFrame filing system abstraction continues to evolve while maintaining its core principles. Whether working with small filing systems or massive distributed data warehouses, the mental model provided by DataFrames remains the foundation of modern data analysis.
Understanding DataFrames deeply doesn’t just make you better at using Pandas—it makes you better at thinking about data organization in general, regardless of the specific tools you’re using.
Next Steps
Ready to put these concepts into practice? Continue with our hands-on implementation guide:
- Pandas DataFrames in Practice: A Comprehensive Implementation Guide - Learn to create, manipulate, and analyze data with real-world DataFrame examples
Additional Resources
Official Documentation
- Pandas DataFrame Documentation - Complete API reference
- Pandas User Guide - DataFrames - Official introduction to DataFrames
- Pandas Cookbook - Common DataFrame operations and patterns
Foundational Concepts
- Tidy Data Paper - Hadley Wickham’s seminal paper on data structure principles
- The Split-Apply-Combine Strategy - Understanding groupby operations conceptually
- Modern Pandas - Tom Augspurger’s comprehensive modern pandas techniques
In-Depth Guides
- Python Data Science Handbook - Chapter 3 - Jake VanderPlas’s foundational pandas guide
- Effective Pandas - Best practices and patterns for DataFrame usage
- Pandas Illustrated - Visual guide to DataFrame operations
Performance and Advanced Topics
- Pandas Performance Tips - Official performance optimization guide
- Why Pandas Uses So Much Memory - Understanding memory usage patterns
- Apache Arrow and Pandas - Next-generation columnar data formats